Additional Bonus Languages: Azerbaijani, Tajik and Armenian
Three new ParaCrawl bonus languages have been released: English-Azerbaijani, English-Tajik and English-Armenian.
Check out the bonus section for low-resource languages.
Check out MultiParacawl 9, including Ukrainian parallel corpora
A new version of the MultiParaCrawl corpus series, including 36 parallel corpora for Ukrainian, has been released.
The MultiParaCrawl corpus is made of parallel corpora from web crawls collected in the ParaCrawl project and further processed for making it a multi-parallel corpus by pivoting via English. It provides the additional language pairs that came out of pivoting.
The recently added bonus language, English-Ukrainian, made it into this release of the MultiParaCrawl corpus and, as a result, 36 parallel corpora for Ukrainian paired with all co-official European languages and others, have also been released.
MultiParaCrawl 9 includes 705 parallel corpora and 41 languages.
This version is derived from the ParaCrawl original release adjusted for redistribution via the OPUS corpus collection. We thank OPUS for this service. To download data files for all language pairs in different formats and with different kind of annotation (if available), please go to https://opus.nlpl.eu/MultiParaCrawl.php
The data is released under the Creative Commons CC0 license ("no rights reserved").
Bonus release: English-Ukranian parallel corpus added
Bonus corpus: English - Ukrainian parallel corpus v1 release
A new parallel corpus covering English and Ukrainian has been released in March 2022.
It has been released as a bonus corpus on behalf of the ParaCrawl effort.
Three versions (Raw, clean TMX and clean TXT) have been produced.
The clean version accounts for 13M sentence pairs and 505M source tokens for both the TXT and TMX formats.
Please download them from the following links:
|
Corpus type
|
Sentence pairs | Source Tokens | Link | Size |
| English-Ukranian, TXT version (TAB separated files) | 13,354,365 | 505,831,880 | paracrawl-clean-en-uk.txt |
2.8G |
| English-Ukrainian, TMX version (XML file) | 13,354,365 | 505,831,880 | paracrawl-clean-en-uk.tmx |
8.3G |
| English-Ukrainian, RAW version | 235,700,383 | 5,832,658,894 | paracrawl-raw-en-uk |
15.3G |
ParaCrawl Corpus Release 7
ParaCrawl 7 is the final release of ParaCrawl Action 2: "Broader Web-Scale Provision of Parallel Corpora for European Languages" and it uses a brand new version of Bicleaner, namely version 0.14 (see full log of changes). Some highlights are as follows:
- new rules have been implemented to filter out noise for, e.g. sentences containing a lot of glued words or inappropriate language
- the classifier uses now a different technology: extremely randomised trees instead of random forest is the default classifier
- classifier features have been improved to better cope with OOVs and make the most of the probabilistic dictionaries
- training procedure has been simplified and logging info messages are now more informative
- access to pre-trained language packs has also been eased
- the 29 available language packs have been updated
Corpora sizes and download links are available from ParaCrawl's website (https://paracrawl.eu/v7).
The latest release of the ParaCrawl OpenSource Pipeline (Bitextor) is available on Github.
Web-Scale Acquisition of Parallel Corpora, ParaCrawl in ACL
The main goal of the ParaCrawl project is to create the largest publicly available corpora by crawling hundreds of thousands of websites, using open source tools. As part of this effort, several open source components have been developed and integrated into the open-source tool Bitextor, a highly modular pipeline that allows harvesting parallel corpora from multilingual websites or from preexisting or historical web crawls such as Common Crawl or the one available as part of the Internet Archive. The processing pipeline consists of the steps: crawling, text extraction, document alignment, sentence alignment, and sentence pair filtering. The ACL paper describes these steps in detail and evaluates alternative methods empirically in terms of their impact on machine translation quality. Hunalign, Bleualign and Vecalign tools are evaluated for the sentence alignment step. Similarly, Zipporah, Bicleaner and LASER are evaluated for the sentence pair filtering step. Benchmarking data sets for these evaluations are also published. The released parallel corpora is also described in the paper and useful statistics are tabulated about the size of the corpora before and after cleaning for different languages. The quality and usefulness of the data is measured by training Transformer-Based machine translation models with Marian for five different languages. Improvements in BLEU scores are reported against models trained on WMT data sets. Furthermore, the energy cost consumption of running and maintaining such a computationally expensive pipeline is discussed and positive environmental impacts are highlighted. The paper aims to contribute to the further development of novel methods of better processing of raw parallel data and to neural machine translation training with noisy data especially for low resource languages.
Watch our pre-recorded talk on ACL2020 Virtual Conference website.
and join the live Q&A sessions on Tuesday, July 7, 2020:
Session 8A: Resources and Evaluation-7 14:00–15:00 CEST
Session 9A: Resources and Evaluation-9 19:00–20:00 CEST
ParaCrawl Corpus Release 6
Release 6 includes a new language pair English-Icelandic with a lot more data for many other languages. Restorative cleaning with Bifixer gets more data by improving sentence splitting, better data by applying fixes to wrong encoding, html issues, alphabet issues and typos and unique data not only identifying duplicates but also near duplicates. Improved Bicleaner models have also been applied to filter out noisy parallel sentences for this release.
Corpora sizes and download links are available from ParaCrawl's website (https://paracrawl.eu/v6).
The latest release of the ParaCrawl OpenSource Pipeline (Bitextor) is available on Github.
The corpus and software are released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English).
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)
ParaCrawl Corpus Release 5.1
Version 5.1 builds upon the same raw corpus as version 5. Thanks to improvements in filtering procedure, the official subset extracted as version 5.1 is now higher in quantity for almost all language pairs (but ga, de, sl and et). Quality measured extrinsically through MT for several language pairs shows also improvement in quality.
Corpora sizes and download links are available from ParaCrawl's website (https://paracrawl.eu/v5-1).
This is the official release to be used in WMT20. Stay tuned for more news and follow us on twitter @ParaCrawl.
The latest release of the ParaCrawl OpenSource Pipeline (Bitextor) is available on Github.
The corpus and software are released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English).
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)
ParaCrawl - A CEF Digital Success Story
EU funding supports ParaCrawl, the largest collection of language resources for many European languages – significantly improving machine translation quality. Read the Success Story published by CEF Digital, titled "ParaCrawl taps the World Wide Web for language resources".
Kick-off meeting of ParaCrawl 3: Continued Web-Scale Provision of Parallel Corpora for European Languages

Last week took place the kick off meeting of the third CEF funded Action aiming at improving and expanding the parallel corpora developed in two previous actions (ParaCrawl-1-Action no 2016-EU-IA-0114 and ParaCrawl-2-Action no 2017-EU-IA-0178). These previous Actions have already resulted in the release of the largest ever publicly available parallel corpora, for all EU/EEA official languages paired with English, as well as a complete end-to-end crawling and extraction open-source software toolkit.
ParaCrawl 3 will offer improved extraction software capable of efficiently processing an even larger portion of the Web (more than 1 compressed petabyte). At the same time, it will apply state-of-the-art neural methods to the detection of parallel sentences, and the processing of the extracted corpora. Special emphasis will be placed on collecting larger corpora for language pairs that are currently under-resourced. The corpora will be made more useful for training machine translation (MT) systems by post-processing the data to split long sentences, repair broken sentences and synthesise new sentences.
The new corpus releases will be made available via a data portal which will allow the users building the machine translation systems to select the types of text which best fit their purpose.
Keep posted!
ParaCrawl corpus release 5
The fifth version of the ParaCrawl corpus has been released. It is the first release under the ParaCrawl action: "Broader Web-Scale Provision of Parallel Corpora for European Languages". The latest release of the corpora contains newly crawled data, including data from Internet Archive. Enhancements in document and sentence aligners with updated BiCleaner strategy resulted in corpora twice the size compare to release v4 for all the official EU languages (23 languages paired with English).
Corpora sizes and download links are available from ParaCrawl's website (https://paracrawl.eu/releases.html).
Following chart shows an overview of the corpora sizes in terms of English word counts: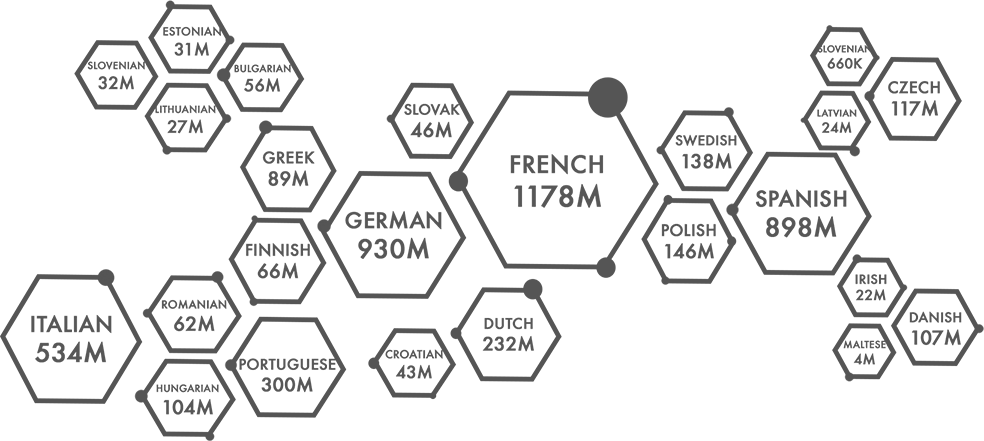
The latest release of the ParaCrawl OpenSource Pipeline (Bitextor) is available on Github.
The ParaCrawl efforts will continue with the Broader Web-Scale Provision of Parallel Corpora for European Languages; focusing on more language pairs, ingesting more file formats beyond HTML, expanding the crawl coverage and applying domain filtering. Stay tuned for more news and follow us on twitter @ParaCrawl.
The corpus and software are released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English).
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)
ParaCrawl works!
NMT experiments are performed for various language pairs, comparing models trained on WMT data with and without the addition of ParaCrawl released corpora. Shallow NMT models, trained with Marian, are used for these experiments. The following table shows that almost in all cases, except for en-cs, addition of ParaCrawl data significantly improves the BLEU scores. The ParaCrawl pipeline has significantly improved since the release 1 and that reflects in the following results as the v4 of the ParaCrawl data is much cleaner, the improvement in BLEU scores is much more evident.
| Pair | Direction | BLEU (WMT) |
BLEU (ParaCrawl v1) |
BLEU (ParaCrawl v4) |
|---|---|---|---|---|
| Finnish-English | en-fi | 17.5 | 17.5 | 18.7 |
| fi-en | 21.7 | 24.2 | 26.3 | |
| Latvian-English | en-lv | 13.2 | 13.9 | 15.1 |
| lv-en | 15.6 | 16.5 | 18.1 | |
| Romanian-English | en-ro | 25.9 | 26.5 | 27.2 |
| ro-en | 31.1 | 33.5 | 35.1 | |
| Czech-English | en-cs | 20.5 | 19.1 | 20.4 |
| cs-en | 25.7 | 26.3 | 26.8 | |
| German-English | en-de | 24.0 | 20.8 | 25.2 |
| de-en | 29.8 | 28.8 | 32.9 |
ParaCrawl corpus release v4.0
The fourth version of the ParaCrawl corpus has been released. It is the final release for the first ParaCrawl project, Provision of Web-Scale Parallel Corpora for Official European Languages, contains parallel corpora for 23 European languages paired with English. The latest release of the corpora brings cutting-edge improvements to the processing pipeline, mainly focusing on getting high-quality bilingual sentences. To that end, extensive cleaning techniques have been applied such as character-based language model filtering or safe restorative cleaning.
Corpora sizes and download links are available from ParaCrawl's website (http://paracrawl.eu/releases.html).
ParaCrawl corpus is hosted by Registry of Open Data on AWS.
The source code of the ParaCrawl OpenSource Pipeline (Bitextor) is available on Github.
The ParaCrawl efforts will continue with the second iteration, Broader Web-Scale Provision of Parallel Corpora for European Languages; focusing on more language pairs, ingesting more file formats beyond HTML, expanding the crawl coverage and applying domain filtering. Stay tuned for more news and follow us on twitter @ParaCrawl.
The corpus and software are released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English).
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)
ParaCrawl corpus is now available on Registry of Open Data on AWS
This registry exists to help people discover and share datasets that are available via AWS resources. Learn more about sharing data on AWS.
![]()
ParaCrawl corpus release v3.0
The thrid version of the ParaCrawl corpus has been released. It contains parallel corpora for 23 languages paired with English. 6 new languages are added to the v3 release namely Bulgarian, Danish, Greek, Slovak, Slovenian and Swedish. For the previously released languages more data is added to the corpus. For each language two different versions of corpus are released based on two cleaning tools, i.e. BiCleaner and Zipporah. ParaCrawl corpus is crawled from a large number of web sites. The selection of websites is based on CommonCrawl, but ParaCrawl is extracted from a brand new crawl which has much higher coverage of these selected websites than CommonCrawl.
Corpus size and download links are available from ParaCrawl's website (http://paracrawl.eu/releases.html). The corpus will soon be uploaded to other public data repositories as well.
The source code of the ParaCrawl OpenSource Pipeline (Bitextor) is also available on Github.
The corpus and software are released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English). Next release is scheduled for March 2019.
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)
ParaCrawl corpus release v2.0
The second version of the ParaCrawl corpus has been released. It contains parallel corpora for 17 languages paired with English. 6 new languages are added to the v2 release namely Irish, Croatian, Maltese, Lithuanian, Hungarian and Estonian. For the previously released languages (German, French, Spanish, Italian, Portuguese, Dutch, Polish, Czech, Romanian and Finnish) more data is added to the corpus. For each language two different versions of corpus are released based on two cleaning tools, i.e. BiCleaner and Zipporah. ParaCrawl corpus is crawled from a large number of web sites. The selection of websites is based on CommonCrawl, but ParaCrawl is extracted from a brand new crawl which has much higher coverage of these selected websites than CommonCrawl.
Corpus size and download links are available from ParaCrawl's website (http://paracrawl.eu/releases.html). The corpus will soon be uploaded to other public data repositories as well.
The source code of the ParaCrawl OpenSource Pipeline (Bitextor) is also available on Github.
The corpus and software are released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English). Updated releases are scheduled for June 2018, October 2018, and March 2019.
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)
Meet ParaCrawl at AMTA Technology Forum!
Prompsit, one of our partners, will attend and exhibit on behalf of ParaCrawl at the next AMTA Conference in Boston (17-21 March 2018). The exhibition is part of the Technology Forum organised inside the AMTA Conference which will take place on 18th March 2018 from 12:30 to 17:30.
By visiting us at AMTA’s Technology Forum:
- you will learn more about the 11 parallel corpora that we already released
- you will see a live demo of some the tools that we will soon release: Bicleaner, a web-based TMX cleaner and KEOPS, an evaluation toolkit for parallel sentences.
Come a visit us at AMTA’s Technology Forum for free!
If you are coming only for the Technology Forum, you just need to select Complimentary Registration on the AMTA registration site.
1st corpus release for ParaCrawl
The first version of the ParaCrawl corpus has been released. It contains parallel corpora for 11 languages paired with English, namely German, French, Spanish, Italian, Portuguese, Dutch, Polish, Czech, Romanian, Finnish and Latvian, crawled from a large number of web sites. The selection of websites is based on CommonCrawl, but ParaCrawl is extracted from a brand new crawl which has much higher coverage of these selected websites than CommonCrawl.
Corpus size, BLEU score evaluations and download links are available from ParaCrawl's website (http://paracrawl.eu/releases.html). The corpus will soon be uploaded to other public data repositories as well.
The corpus is released as part of the ParaCrawl project co-financed by the European Union through the Connecting Europe Facility (CEF). This release used an existing toolchain that will be refined throughout the project and expanded to cover all official EU languages (23 languages parallel with English). Updated releases are scheduled for June 2018, October 2018, and March 2019.
The corpora are released under the Creative Commons CC0 license ("no rights reserved"). (https://creativecommons.org/share-your-work/public-domain/cc0/)